- 서비스 개념
- 서비스 타입
- 서비스 사용하기 ← 오늘 볼 내용
- 헤드리스 서비스
- kube-proxy
3. 서비스 사용하기
ClusterIP
- selector의 label이 동일한 파드들의 그룹으로 묶어서 단일 진입점(Virtual IP)을 생성
- 클러스텉 내부에서만 사용 가능
- type 생략 시 default 값으로 10.96.0.0/12 범위에서 할당됨
아래의 ClusterIP 서비스 yaml 구문에서 type과 clusterIP는 생략해도 상관없다.
쿠버네티스는 기본적으로 type을 명시하지 않으면 ClusterIP로 생성하고 clusterIP를 지정하지 않으면 10.96.0.0/12 대역에서 랜덤으로 할당하여 생성한다.
clusterip-nginx.yaml
# clusterip-nginx.yaml
apiVersion: v1
kind: Service
metadata:
name: clusterip-service
spec:
type: ClusterIP
clusterIP: 10.100.100.100
selector:
app: webui
ports:
- protocol: TCP
port: 80
targetPort: 80
이전 Deployment Controller에서 본 yaml파일을 그대로 사용한다.
# deploy-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-nginx
spec:
replicas: 3
selector:
matchLabels:
app: webui
template:
metadata:
labels:
app: webui
spec:
containers:
- name: nginx-container
image: nginx:1.25
이제 clusterip-nginx.yaml 파일을 실행하면 위 3개의 파드는 10.100.100.100 이라는 하나의 단일 진입점으로 묶이게 된다.
curl 명령으로 위 10.100.100.100 으로 접속하게 되면 ClusterIP는 3개의 파드 중 하나에게 트래픽을 전달하여 nginx의 HTML코드를 반환하게 된다.
# ClusterIP로 curl
curl 10.100.100.100
위 서비스를 통해 우리가 보낸 트래픽이 고르게 분산되어 요청에 대한 처리량이 분산되니 서비스를 안정적으로 제공할 수 있게 되는 것이다.
누구에게 트래픽이 전달되었는지는 로드밸런서나 각 파드의 로그를 확인하면 알 수 있겠지만 모두 동일한 서비스를 제공하는 파드들이므로 굳이 알 필요는 없다.
서비스의 내용을 확인하면 다음과 같다.
service는 svc로 줄여서 쓸 수도 있다.
위 yaml코드에서 의도한대로 10.100.100.100 이라는 가상 IP에 3개의 파드가 묶인 것을 볼 수 있다.
서비스 분산
서비스가 정말로 분산되는 게 맞는지 의심이 될 수 있기에 index.yaml파일을 약간 변경해봄으로 확인해보자.
각 파드의 index.html 파일의 내용을 webui #1, webui #2, webui #3 로 지정한 후에 동일하게 curl 명령으로 요청을 보내면 다음과 같이 표시된다.
요청을 보낼 때 라운드 로빈 방식과 같이 1, 2, 3을 순서대로 전달하는 것이 아니라 랜덤하게 전달하기 때문에 다음과 같이 고르게 분배가 안될 수도 있다.
Scale out
만약 replicas를 3에서 5로 증가시킨다면 어떻게 될까?
# Scale out
kubectl scale deploy deploy-nginx --replicas=5
Cluster IP 서비스가 스스로 인식해서 Endpoints 에 생성된 파드를 추가한다.
replicas를 더 증가시키든 감소시키든 알아서 해결해주므로 건드릴 필요가 없다.
NodePort
- 모든 노드를 대상으로 외부 접속 가능한 포트를 예약
- Default NodePort 범위: 30000 - 32767
- ClusterIP 생성 후 NodePort를 예약
아래 yaml 구문에서 nodePort는 생략해도 상관없다.
다만 생략할 시 Default NodePort 범위 내에서 랜덤으로 할당한다.
nodeport-nginx.yaml
# nodeport-nginx.yaml
apiVersion: v1
kind: Service
metadata:
name: nodeport-service
spec:
type: NodePort
clusterIP: 10.100.100.200
selector:
app: webui
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30200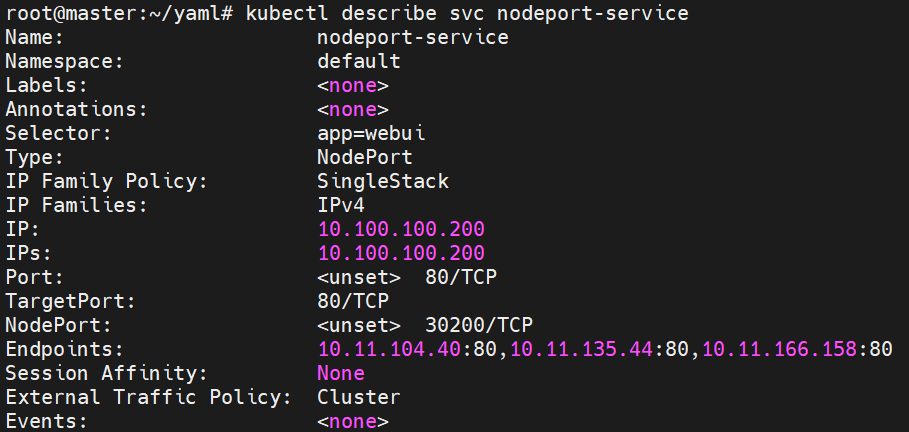
영상에서는 워커 노드에서 netstat -napt | grep 30200 명령을 입력하면 0.0.0.0:30200 으로 포트가 개방되어 있는 내용이 출력이 되는데 내 노드로는 결과가 출력되지 않았다.
하지만 그로 인한 연결이 안된다던가 그렇지는 않고 30200으로 통신은 원활하게 잘된다.
이에 대해 AI에게 물어보았다.
AI의 답변
아, 이해했습니다. curl 명령을 통해 30200 포트로 요청을 보내면 정상적인 응답이 오는데, netstat 명령을 사용하면 해당 포트에 대한 정보가 보이지 않는다는 말씀이군요.
이는 쿠버네티스의 동작 방식과 관련이 있습니다. 쿠버네티스의 NodePort 서비스는 iptables 또는 ipvs를 사용하여 트래픽을 라우팅합니다. 이러한 방식은 커널 레벨에서 동작하기 때문에, 사용자 레벨의 도구인 netstat으로는 확인할 수 없습니다.
따라서 netstat 명령을 사용하여 NodePort 서비스의 포트를 확인하려고 하면 결과가 나오지 않을 수 있습니다. 그러나 curl 등을 사용하여 해당 포트로 요청을 보내면, 쿠버네티스가 해당 요청을 적절한 파드로 라우팅하기 때문에 정상적인 응답을 받을 수 있습니다.
즉, netstat 명령으로 포트를 확인할 수 없다고 해서 해당 포트가 제대로 동작하지 않는 것은 아닙니다. 실제로 서비스가 정상적으로 동작하는지 확인하려면, 실제 요청을 보내 보는 것이 가장 확실한 방법입니다. 이 점 참고하시기 바랍니다.
그렇다고 하니 일단 넘어간다.
실제로 30200포트가 외부로 개방이 되었는지 확인해보자.
외부로 개방이 되었다고 해서 진짜 멀리있는 다른 네트워크의 호스트들이 접근할 수 있는 것은 아니고 클러스터 내부 네트워크에 포함되지 않은 호스트 네트워크(본인 컴퓨터)들도 해당 서비스로 접근이 가능해진다는 말이다.
애초에 나는 VM을 통해서 노드를 구성했기 때문에 각 노드는 사설 IP를 가지고 있어서 외부에서는 접근이 불가능한 것이 당연하다.
먼저 크롬이든 엣지든 아무 브라우저를 열어서 http://<노드 IP>:30200 을 주소창에 입력해본다.
브라우저로 열어도 되고 명령 프롬프트에서 curl <노드 IP>:30200을 입력해도 된다.
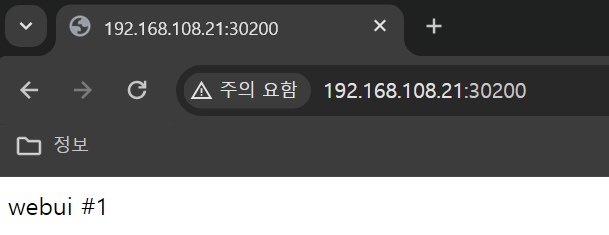

이와 같이 클러스터 내부에 포함되지 않은 외부 네트워크에서도 파드로 접근이 가능하게 되었다.
이것이 NodePort 의 역할이다.
LoadBalancer
- Public 클라우드(AWS, Azure, GCP 등)에서 운영가능
- LoadBalancer를 자동으로 구성 요청
- NodePort를 예약 후 해당 nodeport로 외부 접근을 허용
이는 우리가 지금 구성할 수 있는 것은 아니다.
지금 실제로 운영해볼 수는 없지만 yaml파일을 통해서 구성 내용을 확인해보자.
loadbalancer-service.yaml
# loadbalancer-service.yaml
apiVersion: v1
kind: Service
metadata:
name: loadbalancer-service
spec:
type: LoadBalancer
selector:
app: webui
ports:
- protocol: TCP
port: 80
targetPort: 80
NodePort 서비스와 비교해서 보면 PORT(S) 필드에 nodeport가 하나 랜덤하게 할당된 것을 볼 수 있고 CLUSTER-IP 필드에 10.103.202.255라는 ClusterIP가 랜덤하게 할당되었다.
하지만 우리가 실제 로드밸런서를 연결하지 않았기에 EXTERNAL-IP는 pending 상태인 것을 볼 수 있다.
ExternalName
- 클러스터 내부에서 External(외부)의 도메인을 설정
지금까지는 ClusterIP라는 가장 작은 서비스 단위부터 NodePort, 가장 큰 LoadBalancer까지 서비스가 확장되는 구조를 알아봤다.
하지만 지금 볼 ExternalName은 성격이 조금 다르다.
이는 클러스터 내부에서 외부로 나갈 때 지정한 도메인 네임으로 나갈 수 있게 하는 서비스다.
이해하기 쉽게 설명하면 다음과 같다.
ExternalName 서비스를 생성할 때 google.com 이라는 도메인을 지정하여 생성하면 해당 서비스의 이름을 입력했을 때 실제 google.com 으로 리다이렉트 시켜주는 역할하게 된다.
실습을 통해 알아보자.
externalname-service.yaml
# externalname-service.yaml
apiVersion: v1
kind: Service
metadata:
name: externalname-service
spec:
type: ExternalName
externalName: google.com
임의의 파드를 생성해서 파드 내부로 접속 후 서비스의 이름을 입력해보자.
kubectl run testpod -it --image=centos:7 # 생성과 동시에 내부로 접속
curl externalname-service.default.svc.cluster.local # 서비스의 이름을 curl로 요청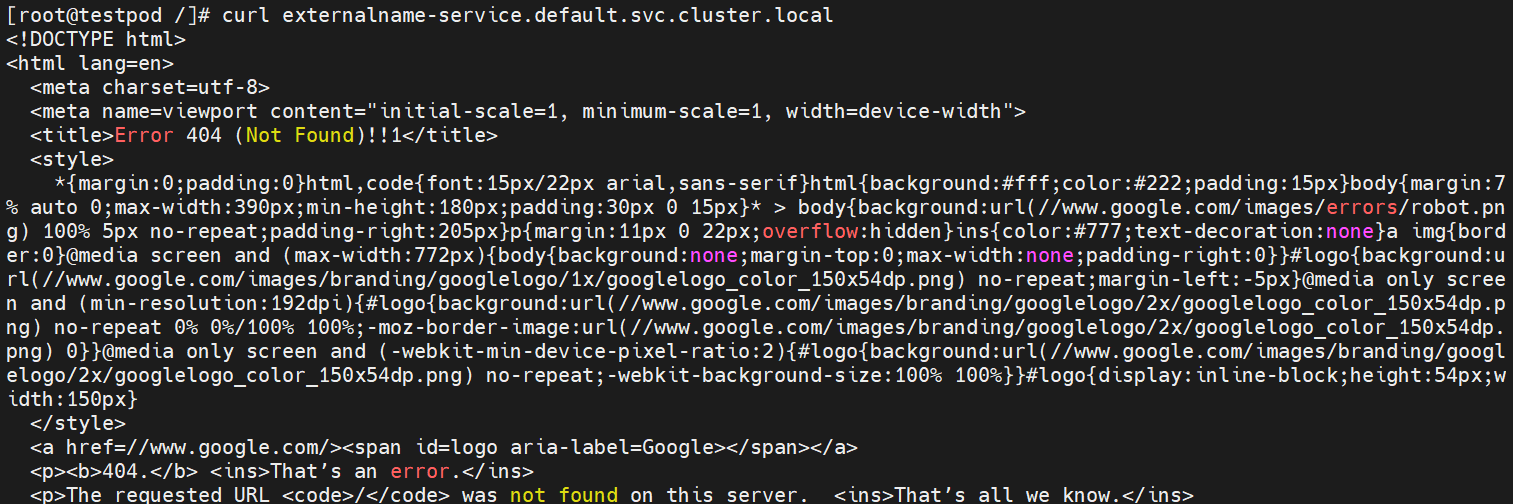
실제로 서비스의 이름으로 curl 요청을 보내면 google.com의 html 코드를 볼 수 있다.
결론적으로 Service는 파드들을 묶어주는 Virtual IP라고 기억하면 된다.
리소스 정리
지금까지 했던 리소스를 모두 정리한다.
사실 지금까지 작성했던 포스트에서는 까먹어서 언급하지 않았지만 항상 실습 후에는 리소스를 정리하는 습관을 기르자.
# 리소스 정리
kubectl delete svc --all
kubectl delete pod testpod
kubectl delete -f deploy deploy-nginx.yaml
아래 영상을 참고했습니다.
https://youtube.com/playlist?list=PLApuRlvrZKohaBHvXAOhUD-RxD0uQ3z0c&si=hbPclcPuc-6lTNdE
[따배쿠] 쿠버네티스 시리즈
www.youtube.com
'Kubernetes' 카테고리의 다른 글
| Kubernetes 기초 - Ingress(1) (0) | 2023.12.20 |
|---|---|
| Kubernetes 기초 - Service(3) (0) | 2023.12.19 |
| Kubernetes 기초 - Service(1) (0) | 2023.12.18 |
| Kubernetes 기초 - Controller(7) (0) | 2023.12.15 |
| Kubernetes 기초 - Controller(6) (0) | 2023.12.15 |