- 로깅 ← 오늘 볼 내용
- 쿠버네티스 대시보드
- 쿠버네티스 클러스터 모니터링
1. 로깅
쿠버네티스 환경에서 로그는 클러스터 내에서 발생하는 이벤트 및 애플리케이션의 출력을 기록하는 데 사용된다.
기존 레거시 환경에서의 로그 관리는 web - was - db 각 티어마다 로그를 기록하고 해당 로그를 logrotate와 같은 툴을 사용하여 관리하는 것이 일반적이었다.
하지만 쿠버네티스 환경에서는 컨테이너 기반 서비스가 운영되기 때문에 각 파드에서 생성되는 로그들을 수집하고 정제하고 저장하는 과정이 필요하기에 기존 로그 관리 방법으로는 부족한 면이 있다.
그리고 로그를 모니터링하여 분석할 수 있는 환경도 필요하다.
클러스터 환경에서의 로그 운영에는 여러가지 내용들이 존재한다.
파드들이 어느 노드에서 실행되었는가? 얼마나 많은 리소스를 사용했는가? 응답 속도가 어떻게 되며 응답 코드는 어떠한가? 등 다양한 이벤트들이 기록될 것이다.
기존 레거시 환경에서의 로그 관리와 클러스터 로그 관리 방법은 다르다.
로그는 kubectl logs 명령을 통해 확인할 수 있다.
실습
# Deployment와 ClusterIP를 생성
kubectl create deploy my-nginx --image nginx:1.25 --port 80 --replicas 2
kubectl expose deploy my-nginx --port 80 --target-port 80
kubectl get pods
kubectl get svc

위와 같은 상황에서 curl 명령을 통해 클러스터 IP로 세 번의 클라이언트 커넥션 요청을 보낸다.
curl <Cluster IP>
curl <Cluster IP>
curl <Cluster IP>
생성된 두 개의 파드 중 하나는 클라이언트 커넥션 이벤트가 두 번 발생했을 것이고 하나는 한 번만 발생했을 것이다.
이것을 로그로 확인해보자.
kubectl logs <파드의 ID>

다음과 같이 개별적인 파드의 로그는 kubectl logs 명령을 통해 확인할 수 있다.
하지만 하나씩 로그를 확인하기에는 불편한 면이 있다.
그래서 모든 로그를 하나로 통합해서 모니터링하고 관리할 수 있는 방법도 존재한다.
EFK를 통한 Kubernetes Application 로그 관리
EFK는 Elasticsearch, Fluentd, Kibana의 약어로, 로그 수집, 분석, 시각화를 위한 오픈 소스 스택을 나타낸다.
각각의 구성 요소는 특정 역할을 수행하며, 이 스택은 로그 관리 및 분석에 필요한 도구들을 포함하고 있다.
- Elasticsearch:
- 역할: 분산 검색 및 분석 엔진으로, 대량의 데이터를 신속하게 저장하고 검색할 수 있는 기능을 제공
- 사용 사례: 로그 데이터를 저장하고 검색하여 빠르게 쿼리하거나 시각화하기 위해 사용
- Fluentd:
- 역할: 다양한 소스에서 로그 데이터를 수집하고 Elasticsearch 또는 다른 저장소로 전송하는 역할
- 사용 사례: 로그 데이터를 수집하고 중앙 집중식으로 전송하여 효율적으로 관리하고 분석하는 데 사용
- Kibana:
- 역할: Elasticsearch에서 저장된 데이터를 시각적으로 탐색하고 대시보드를 작성하는 데 사용
- 사용 사례: 로그 데이터를 시각화하고 검색하기 위해 사용되며, 사용자는 대시보드를 통해 데이터의 상태 및 동향을 쉽게 이해할 수 있음
로그를 수집하는 스택을 무엇을 썼냐에 따라 EFK라고 하기도 하고 ELK라고 하기도 한다(둘 다 쓰는 경우도 있음).
ELK는 로그 수집 스택을 Logstash를 사용한 것으로 Logstash는 다양한 소스에서 로그 및 이벤트 데이터를 수집하고, 변환하며, Elasticsearch 또는 다른 저장소로 전송하는 역할을 한다.
구축하는 법에 대해서는 다음 링크를 참조하여 구성하면 된다.
https://waspro.tistory.com/762
ElasticSearch를 활용한 Kubernetes 로깅 환경 구성
개요 MSA 환경에서 Telemetry의 중요성은 이미 수많은 포스팅과 수많은 포스터들로 부터 강조되어 왔으며, 이미 많은 자료들을 통해 활용 방안들이 다뤄지고 있다. Telemetry는 로깅, 모니터링, 추적
waspro.tistory.com
다만 몇가지 추가 및 수정해야 할 부분이 있다.
저 당시 환경과 현재의 환경의 차이가 있을 수 있으므로 반드시 확인해야 할 부분이다.
ElasticSearch-master를 구성한 이후 ElasticSearch-data를 구성하기 이전에 퍼시스턴트 볼륨을 정의해야 한다.
아래 yaml코드를 복사하여 실행한다.
# pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
persistentVolumeReclaimPolicy: Recycle
storageClassName: gp2
hostPath:
path: /logdata
이후 계속 절차대로 실행하다가 fluentd를 구성할 때 변경해야 할 것이 있다.
현재 나의 쿠버네티스 버전은 1.29, 컨테이너 런타임은 containerd를 사용하고 있다.
이러한 환경의 차이에 따라 기록되는 로그의 포맷이 달라질 수 있으니 로그를 수집하는 fluentd가 제대로 로그를 수집하기 위해서는 fluentd의 설정에 형식을 맞춰주어야 한다.
현재 나의 쿠버네티스 로그의 포맷은 다음과 같다.
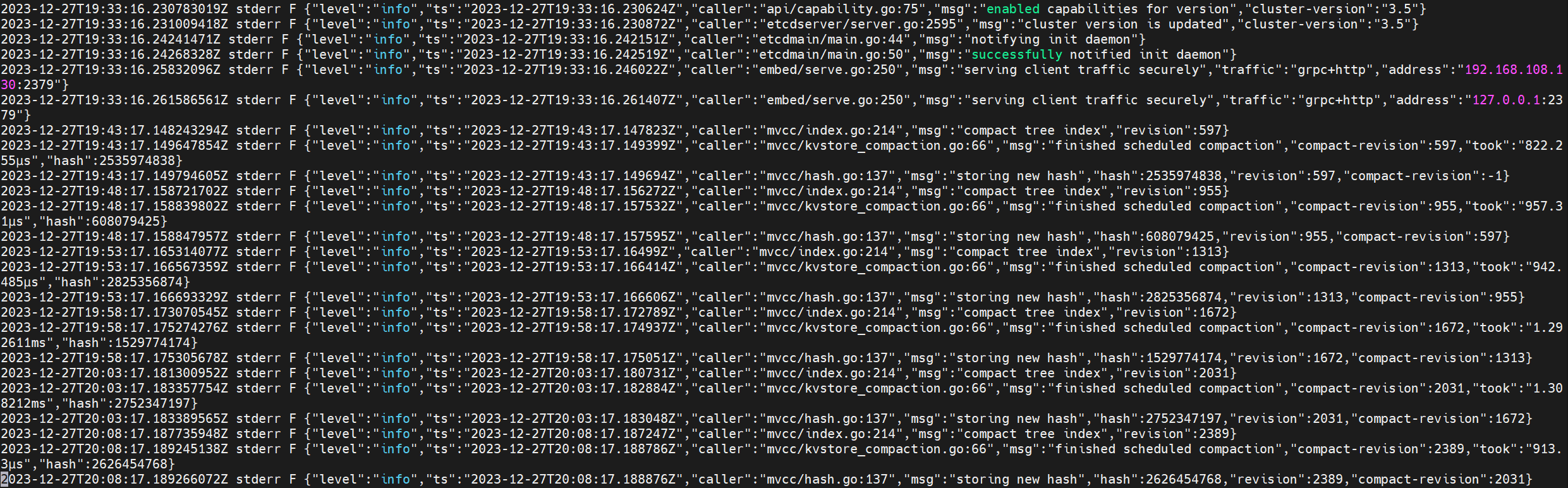
쿠버네티스에서 로그는 /var/log/containers/* 디렉토리 아래에 존재하므로 자신의 쿠버네티스 클러스터는 로그의 형식이 어떤지 확인하고 반드시 로그 포맷을 fluentd에게 올바르게 알려주어야 한다.
자신의 로그가 포맷이 어떤지 모르겠으면 로그를 복사해서 ChatGPT한테 물어보자.
다음과 같이 수정한다.
# fluentd-config-map-custome-index.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
namespace: kube-logging
data:
fluent.conf: |
<match fluent.**>
# this tells fluentd to not output its log on stdout
@type null
</match>
# here we read the logs from Docker's containers and parse them
<source>
@type tail
path /var/log/containers/*
pos_file /var/log/containers.log.pos
tag kubernetes.*
read_from_head true
<parse>
@type regexp
expression /^(?<timestamp>\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d+Z) (?<log_level>\S+) (?<log_content>.+)$/
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
# we use kubernetes metadata plugin to add metadatas to the log
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match kubernetes.var.log.**kube-logging**>
@type null
</match>
<match kubernetes.var.log.**kube-system**>
@type null
</match>
<match kubernetes.var.log.**monitoring**>
@type null
</match>
<match kubernetes.var.log.**infra**>
@type null
</match>
# we send the logs to Elasticsearch
<match kubernetes.**>
@type elasticsearch_dynamic
@log_level info
include_tag_key true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER']}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD']}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
ssl_verify "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERIFY'] || 'true'}"
reload_connections true
logstash_format true
logstash_prefix ${record['kubernetes']['pod_name']}
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever true
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 32
overflow_action block
</buffer>
</match>
parse 부분에 기존 json으로 되어있는 것을 수정한다.
# 기존의 parse 블럭
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
# 수정 후 parse 블럭
<parse>
@type regexp
expression /^(?<timestamp>\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d+Z) (?<log_level>\S+) (?<log_content>.+)$/
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
이렇게 하면 fluentd를 통한 정상적인 로그 수집이 가능하게 된다.
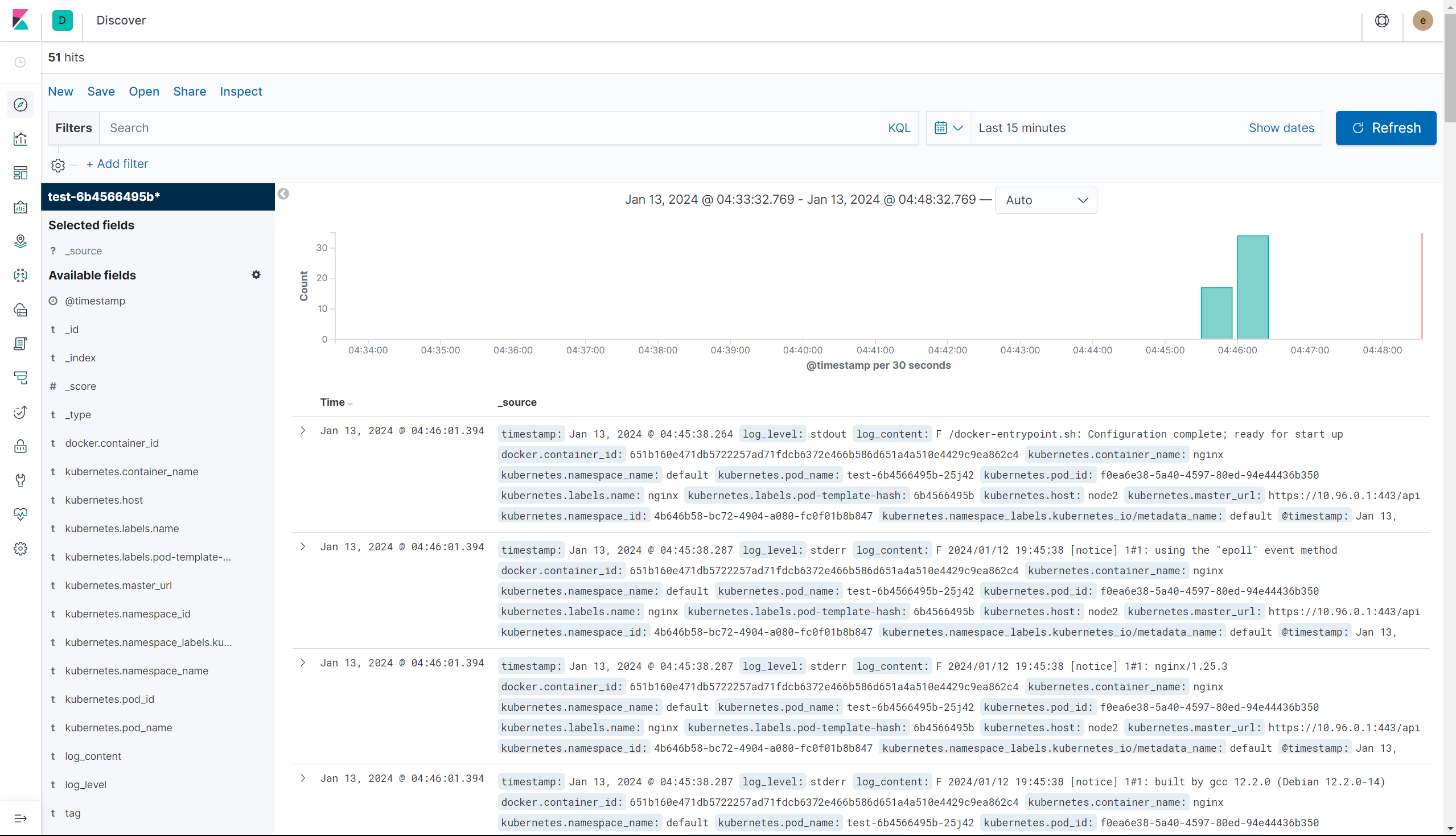
while [ true ]; do curl <파드의 IP> > /dev/null 2>&1; sleep 0.5; echo "success!"; done
이제 curl명령으로 마음대로 접속해보면서 로그가 정말 수집되는지 확인해보면 된다.
아래 영상을 참고했습니다.
https://youtube.com/playlist?list=PLApuRlvrZKohLYdvfX-UEFYTE7kfnnY36&si=gffS-BhQgI-DRova
[따배쿠 Advance] 쿠버네티스 심화 시리즈
www.youtube.com
EFK 스택에 대한 다른 참고 자료
https://devopscube.com/setup-efk-stack-on-kubernetes/
How to Setup EFK Stack on Kubernetes: Step by Step Guides
In this Kubernetes tutorial, you’ll learn how to setup EFK stack on Kubernetes cluster for log streaming, log
devopscube.com
'Kubernetes' 카테고리의 다른 글
| Kubernetes 기초 - Scheduling(1) (0) | 2024.01.03 |
|---|---|
| Kubernetes 기초 - 로깅과 모니터링(2) (0) | 2024.01.02 |
| 멀티 마스터 쿠버네티스 클러스터 구성 방법 (0) | 2023.12.31 |
| Kubernetes 기초 - Secret (0) | 2023.12.23 |
| Kubernetes 기초 - ConfigMap (0) | 2023.12.23 |